ChatGPTs avanserte evner, som for eksempel feilsøking av kode, skrive en essay eller lage en spøk, har ført til massiv popularitet. Til tross for sine evner, har hjelpen hittil vært begrenset til tekst – men det er i ferd med å endre seg.
Tirsdag presenterte OpenAI GPT-4, en stor multimodal modell som aksepterer både tekst- og bildeinndata og gir tekstutdata.
Også: Slik får du ChatGPT til å oppgi kilder og sitater
Forskjellen mellom GPT-3.5 og GPT-4 vil være "subtil" i uformell samtale. Imidlertid vil den nye modellen være mye mer kapabel når det gjelder pålitelighet, kreativitet og til og med intelligens.
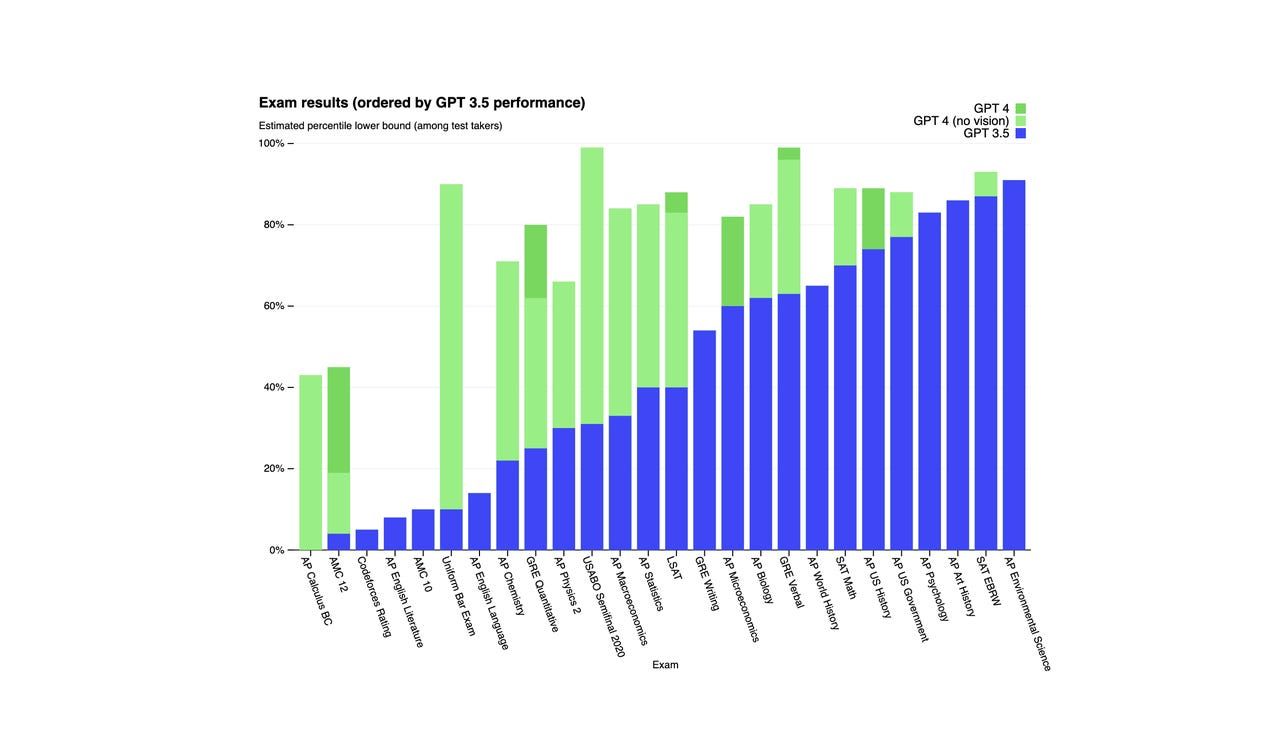
I følge OpenAI, oppnådde GPT-4 en plassering blant de øverste 10% på en simulert advokateksamen, mens GPT-3.5 havnet blant de nederste 10%. GPT-4 presterkte også bedre enn GPT-3.5 i en rekke benchmark-tester, som vist i diagrammet nedenfor.

For å ha kontekst, kjører ChatGPT på en språkmodell som er finjustert fra en modell i 3.5-serien, som begrenser chatboten til tekstoutput.
OpenAI's GPT-4 kunngjøring fulgte etter en tale fra Andreas Braun, CTO i Microsoft Tyskland, forrige uke, der han sa at GPT-4 snart ville komme og tillate muligheten for tekst-til-video-generering.
Også: Hvordan fungerer ChatGPT?
"Vi vil introdusere GPT-4 neste uke; der vil vi ha multimodale modeller som vil tilby helt forskjellige muligheter -- for eksempel videoer," sa Braun ifølge Heise, en tysk nyhetskanal under arrangementet.
Tross GPT-4 som er multimodal, var påstandene om en tekst-til-video-generator litt feil. Modellen kan ikke helt produsere video ennå, men den kan akseptere visuelle innganger, noe som er en betydelig endring fra forrige modell.
Ett av eksemplene som OpenAI ga for å vise denne funksjonen, viser ChatGPT som skanner et bilde i et forsøk på å finne ut hva som er morsomt med bildet, basert på brukerens inndata.
Andre eksempler inkluderer opplasting av et bilde av en graf og be om at GPT-4 gjør beregninger ut ifra det, eller opplasting av et regneark og be om at det løser oppgavene.
Også: 5 måter ChatGPT kan hjelpe deg med å skrive en essay
OpenAI sier at de vil slippe GPT-4's tekstinngangsfunksjon via ChatGPT og API-en via en venteliste. Du må vente litt lenger for bildeinngang-funksjonen, siden OpenAI samarbeider med en enkelt partner for å få den startet.
Hvis du er skuffet over å ikke ha en tekst-til-video-generator, ikke bekymre deg, det er ikke en helt ny idé. Teknologigiganter som Meta og Google har allerede modeller i arbeid. Meta har Make-A-Video og Google har Imagen Video, som begge bruker kunstig intelligens til å produsere video basert på brukerinput.